機械学習には大きく3つあります。
- 教師あり学習:答えデータを与えて答えを予測する
- 教師なし学習:特徴データから答えのないところからマッピング
- 強化学習:たくさん経験して学んでいく
違いにについては『意外と知らない機械学習の基礎知識・種類|データサイエンティストのスキルを身につける』にまとめてあります。
この記事では教師なし学習の基本である「グループ分類」について説明します。
以下に当てはまる方は参考にしてください。
- 機会学習ってどんなの?
- 教師なし学習ってなに?
- グループ分けってどうやるの?
- クラスタリングするコードを見てみたい
まずは機械学習の中でグループ分類とはどういうものなのか、利用用途について紹介します。
なにができて、なにができないのか説明するので、目的に合っているのか確認してください。
次に分類の種類について概要を説明します。
目的に合わせて、何を学べばよいのか判断基準にしてください。
最後に分類の種類の1つ、階層化クラスタリングの簡単なサンプルコードを紹介します。
実際にどういったことをやっていくのかイメージするのに参考にしてください。
グループ分類とは – 利用用途 –

グループ分類は「教師なし学習」の1つです。
「教師あり学習」については『【機械学習の基本】値予測のやり方を解説|1次関数の傾きと切片を求める』を参考にしてください。
「教師なし学習」は「教師あり学習」と違って、答えのないものを分析します。
データの構造からパターンをみつけて、自動的に分類してくれるものです。
あくまで、分類してくれるだけであり、数値を予測したり答えを教えてくれるものではないことに注意してください。
具体的には各データの距離を求めて、近いものでまとめる作業になります。
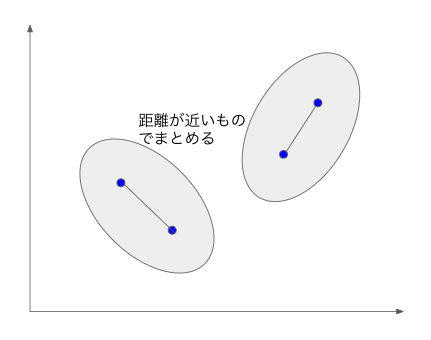
3つ以上のデータでまとめる場合は中心点からの距離で計測します。
利用用途
「グループ分類」はデータを分類して絞りこむことができます。
よくある用途として、教師あり学習で値を予測する前にデータを分類しておき、予測の精度を高める使い方があります。
グループ分類でデータをまとめて、分類したデータを元に、値を予測するモデルを作成することで、値を予測していくのです。
分類の種類
分類の種類は大きく2つあります。
- 階層化クラスタリング
- 非階層化クラスタリング
「階層化クラスタリング」は決められたものなく、データをひたすら分類していく方法です。
イメージとしては、階段のように下から順番に上に積み上げていくようなものです。
あとでサンプルコードでどのようになるのか紹介します。
「非階層化クラスタリング」は事前に分類数を指定しておき、それに合わせて分類する方法です。
先に決めたものに対して分類していく形になります。
階層化クラスタリングのサンプルコード
実際に「階層化クラスタリング」を実施していきます。
どのように分類されるのか実際に確認してください。
4人の「国語、英語、数学、物理」のテスト結果を分類してきます。
上から実行していけば動くようになっているので、手元でもお試しください。
まずは必要なモジュールを読み込んでいきます。
import numpy as np
import pandas as pd
from scipy.cluster.hierarchy import dendrogram, linkage
import pylab as plt「NumPy」「Pandas」「DataFrame」については以下で説明しています。
・【NumPy入門】機械学習はここから始める|計算方法、配列の作り方、配列の変形
・【Pandas入門】機械学習の基礎知識 -効率的な学習法-|調べて実践できる
分類するテストのデータを用意していきます。
data = pd.DataFrame({'国語':[65,80,92,58],
'英語':[88,37,92,63],
'数学':[65,67,59,72],
'物理':[87,92,56,83]},
index=['Aさん','Bさん','Cさん','Dさん'])表にするとこのようになります。
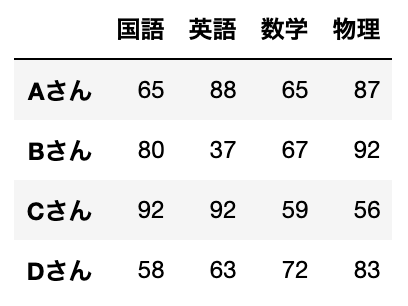
表だけみても、なにをどうしてよいやら、、、ですね。
では実際に分類して図にしていくのですが、図に日本語を表示するために文字を用意しておきます。
まずはこちらよりフォントをダウンロードしてください。
サーバ上で以下のコマンドを実行してPythonで利用できるようにしましょう。
「”○○”」の部分は自分の環境に合わせて変更してください。
$ unzip ~/Downloads/”ダウンロードしたZIP”
$ mv ~/Downloads/”解凍したもの”/ipaexg.ttf ~/anaconda3/lib/”Pythonのバージョン”/site-packages/matplotlib/mpl-data/fonts/ttf
$ rm -f ~/.matplotlib/fontList.py3k.cache ※jupyter notebook を使っている場合は再起動してください
分類するにはSciPyの「linkage関数」を利用します。
result = linkage(data)とてもシンプルですね。
引数でいろいろと指定することができるのですが、この記事ではデフォルトの設定を使用します。
引数などについてはこちらを参考にしてください。
今回の結果をテキストでみるとこのようになります。
array([[ 1. , 2. , 21.65640783, 2. ], [ 0. , 3. , 27.18455444, 2. ], [ 4. , 5. , 31.22498999, 4. ]])
これだけみても何がなんだか、わからないですよね。。。
見方をまとめると以下のようになります。
- [1],[2]つまりBさん、Cさんが距離21.65640783でまとまった
- [0],[3]つまりAさん、Dさんが距離27.18455444でまとまった
- 全体が距離31.22498999でまとまる
といってもわかりづらいですよね。。。
そこで樹形図にしてみましょう。
樹形図は「階層化クラスタリング」での考え方に合っているので、是非参考にしてください。
name = ('Aさん','Bさん','Cさん','Dさん')
#樹形図の構築
dendrogram(
result,
leaf_rotation=90., # 縦軸のラベルを回転
leaf_font_size=14.,
labels=name)
# 文字指定
plt.rcParams["font.family"] = "IPAexGothic"
# 図表示
plt.show()実行すると以下の図が表示されます。
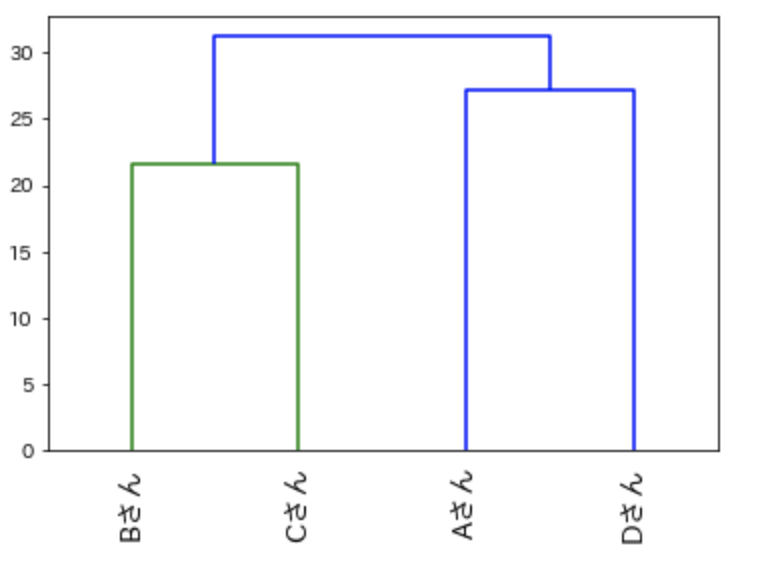
y軸はデータの距離を表しています。
Bさん・Cさんのグループのほうが、Aさん・Dさんのグループより距離が近いことがわかります。
簡単なグループ分けについて紹介してきました。
この他にもいろいろな方法があるので、また紹介していきます!
最後に
機械学習には「回帰分析」「グループ分類」「ディープランニング」など様々な手法があります。
自分の目的に合わせて勉強していく必要があります。
統計学など、いろいろな知識が必要なので、細かいところから独学で勉強していくのはかなりムズカシイです。。。
体系的に学ぶことのできる講座を受けることで、早く、正確に学習することができます。
そこで、ぼくも利用している『Udemy![]() 』を紹介します。
』を紹介します。
オススメできる点はこちらです。
- セール中で安い(1,000円代)
- オンライン講座なのでいつでもどこでも
- 買い切りで何回でも受けられる
- 講座数が多いから目的に合う
本来は1万円代の講座も現在セール中で1,000円代で購入できます!
全部で10万以上もの講座があるので、自分の目的にあった講座が見つかります。
セール中のうちに利用してみてください。
最後まで読んでくださり、ありがとうございました!!!


コメント