
機械学習の需要は徐々に高まっています。
機械学習では多くのデータを扱うため、データをまとめて、効率的に行うことが必須条件です。
この記事ではPythonのモジュール「DataFrame」データを結合(マージ)できる「merge関数」の使い方を紹介します。
- Pythonでデータ分析したい
- 機械学習のスキルをつけたい
- DataFrameの使い方を知りたい
- DataFrameのデータ結合ってどうするの?
機械学習、データ分析といってもPython、統計学、データの扱い方など多くのことを学ぶ必要があります。
最後に一貫した勉強方法を紹介しますね!
※サンプルコードは上から順番に実行すれば同じ結果が得られるようになっています。
自分の手元でデータを変えたりしながら、動かすと理解が深まるので、試してください!
事前準備 〜モジュールのインポート〜
「DataFrame」を使うには「NumPy」 「Pandas」をインポートする必要があります。
(正確には「NumPy」は必須ではありませんが、利用しないことはまずないでしょう)
以下のコードを実行してください。
import numpy as np
import pandas as pd
from pandas import DataFrame
「NumPy」については↓↓↓をご覧ください。

「Pandas」については↓↓↓をご覧ください。
「DataFrame」の基本についても説明しています。

データの準備から簡単なデータ結合
まず以下のコードを実行してデータを準備します。
値を変えたり、構造を変えたりして試してみてください。
df1 = DataFrame({'key' : ['A', 'B', 'C', 'B', 'A', 'A'], 'data1' : np.arange(6)})
df2 = DataFrame({'key' : ['D', 'A', 'C'], 'data2' : [1,2,3]})“df1″、”df2″という「DataFrame」型のデータが作成されます。
このデータを結合していきます。
結合にはPandasの「merge関数」を利用します。
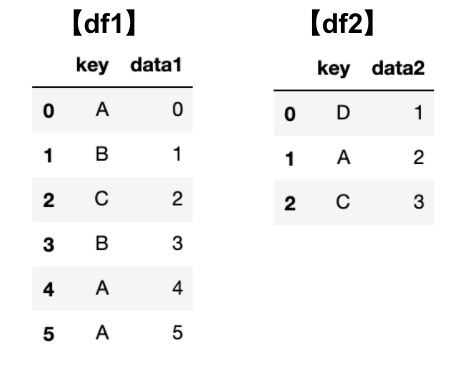
pd.merge(df1, df2)結果はこのようになります。
共通して存在する列で自動的にまとめられます。
今回の例では”key”列が共通してるので、両方のデータで共通している”A”、”C”でまとめられています。
片方にしかない”B”、”D”はなくなっています。
結合する基準データの設定
先ほどは共通して存在する列で自動的に結合されましたが、共通項目を指定することこができます。
引数に「on=’共通項目とする列名’」を入れると設定できます。
pd.merge(df1, df2, on='key')これで明示的に「key」を基準とする列にでき、先ほどの例と同じ結果になります。
また、先ほどは”df1″、”df2″どちらも同じレベル感の基準で結合しましたが、引数に「how=’○○’」を入れることで設定できます。
○○の部分は以下があります。
- left
- right
- inner
- outer
それぞれどうなるのか解説してきます。
最初に作成した利用するデータを表示しておきます。
【引数】how=’left’
引数で指定したデータのうち、1つ目の引数に指定したデータが基準となります。
実際に実行して確認します。
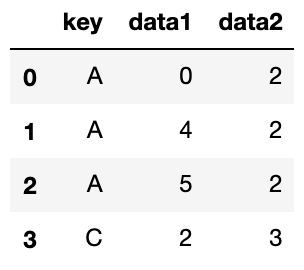
pd.merge(df1, df2, on='key', how='left')結果はこのようになります。
1つ目の引数に指定した“df1″を基準にマージされています。
そのため、”df1″で設定されおり、”df2″には設定されていないものもあります。
その場合は「NaN」がはいります。
「NaN」については↓↓↓をご覧ください。

“df2″のみで設定されているものはなくなります。
【引数】how=’right’
なんとなく想像できると思います。
“left”が1つ目の引数であったのに対し、“right”の場合は2つ目の引数が基準となります。
動かして確認します。
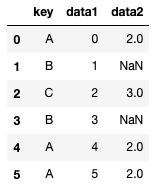
pd.merge(df1, df2, on='key', how='right')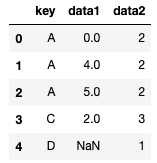
“df2″が基準になっていることがわかると思います。
引数の順番を変えてもいいですが、”how”を利用して明示的に指定すると読みやすいコードになります。
【引数】how=’inner’
‘inner’を指定した場合は”how”を指定しないときと同じ状態になります。
つまりデフォルトで設定されています。
SQLでいう「内部結合」と同じ状態です。
1つ目の引数、2つ目の引数どちらにもあるものが入ります。
【引数】how=’outer’
‘inner’が内部結合だったのに対し’outer’は「外部結合」の状態になります。
実際に動かしてみましょう。
pd.merge(df1, df2, on='key', how='outer')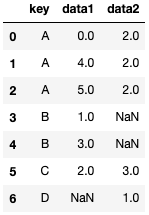
1つ目の引数、2つ目の引数どちらかにあれば、はいります。
値がないところには「NaN」がはいります。
つまり全部の要素がはいる形になります。
複数の共通項目を指定
これまでは作成したデータの’key’を共通項目としてマージしてきました。
複数の共通項目を指定することもできます。
新しいデータを作成します。
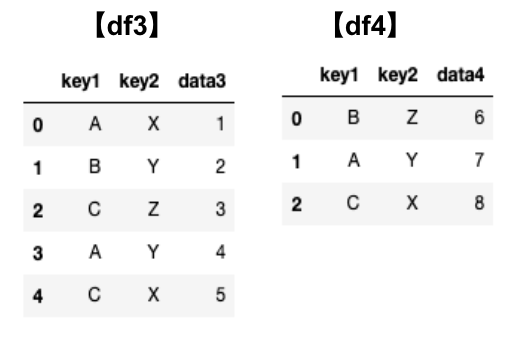
df3 = DataFrame({'key1' : ['A', 'B', 'C', 'A', 'C'],
'key2' : ['X', 'Y', 'Z', 'Y', 'X'],
'data3': [1, 2, 3, 4, 5]})
df4 = DataFrame({'key1' : ['B', 'A', 'C'],
'key2' : ['Z', 'Y', 'X'],
'data4': [6, 7, 8]})表にするとこのようになります。
複数の共通項目を指定するには引数”on”を配列で指定します。
‘key1’と’key2’を共通項目にしてマージしてみます。
pd.merge(df3, df4, on=['key1', 'key2'])このように’key1’と’key2’を共通項目として、基準データは’inner’状態のデータができます。

‘key1’と’key2’で’df3’、’df4’どちらにもあるものだけ残ります。
【+α】マージ元のデータに同じ名前の項目がある場合
‘key1’と’key2’を共通項目があり、両方を指定しました。
片方だけした場合はどうなるのでしょうか。
‘key1’だけ指定してみます。
pd.merge(df3, df4, on='key1')このように‘key2’の項目名が、1つ目の引数(df3)は’_x’がつき、2つ目の引数(df4)は’_y’がつきます。
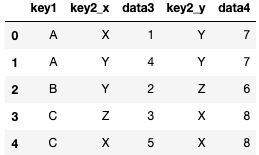
これは自動的につけられます。
「suffixes=[‘〇〇’, ‘△△’]」を指定することで、項目名につくものを指定することもできます。
試しにやってみます。
pd.merge(df3, df4, on='key1', suffixes=['_3', '_4'])このように設定しました。
- df3 → _3
- df4 → _4
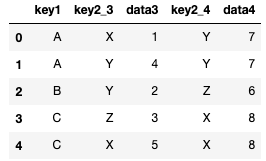
是非、値や構造を変えて試してみてください!
効率的に最短で学習する方法
機械学習だけでなく、プログラミングを学習するには共通した方法があります。
流れはこのようになります。
- 全体像を把握する
- ローカルで試しに動かしてみる
- わからないことを予想して調べる
- 調べてことを動かして試す
- ローカルで完成したら本番に移行する
一番身につける必要があるスキルは「3.わからないことを予想して調べる」になります。
できるプログラマとできないプログラマの違いは「わからないことの予想の質」です。
- できる人 → 広い知識から解決方法を予測できる
- できない人 → 解決方法の予想ができないので、ひたすら実行
そこで重要なのが「1.全体像を把握する」です。
全体像がわかっていたら、どのあたりが問題でどうすればよいのか予想できるようになります!
しかし、独学で全体像を把握しようとしても、書籍などでは1つのことにフォーカスされたものばかりでかなり時間がかかります。。。
個人で集中的に学習:Udemy
そこで、ぼくも利用している『Udemy ![]() 』を紹介します。
』を紹介します。
これまで3000万人以上が利用しており、全部で10万もの講座があります。
目的に応じて集中的に学習することができます!
オンラインで受講できるため、出勤中などに学習することもできます。
さらに、年に数回セールスを実施しており、その間は1,000円代で講座を購入することができます!
オンライン講座では圧倒的に安いので、いまのうちに利用してみてください。
Udemyの概要や利用方法は↓↓↓を参考にしてください。

Pythonに特化(初心者向け):PyQ
Pythonの基礎から学びたい方は『PyQ』がオススメです!
オススメのポイントはこちらです。
- 技術書1冊分の費用で学べる
- Pythonでできることはすべて学べる
- 初心者向きに解説されてる
PyQのメリット・デメリットは↓↓↓をご覧になってください!

最後に
この記事ではデータ分析、機械学習の基礎技術「データの結合(マージ)」について説明しました。
Pythonを利用して何かする際は必ずといっていいほど、使う技術になるので、必ず本質を理解しておいてください。
一つのことを調べながら学習していく方法もよいですが、一貫した内容を学べる教材があったほうが早くスキルを身につけることができます。
なるべく安く、効率的に学べる講座を探してみてください。
最後まで読んでくださり、ありがとうございました!!!


コメント