
Python初心者が最初につまづくのが「NaN」という値です。
普段、生活していく上で使わなかった概念になるので、イメージが難しいですが、どういったものなのか説明していきます。
以下に当てはまる項目がある方は是非参考にしてください!
・Pythonを学習中
・NaN値とNoneの違いがわからない
・NaNに関してなにができるのか知りたい
具体的には「NaN」とは何かを説明した後、似た「None」との違いを解説していきます。
しばらくPythonに触れている人でも知らないこともあると思うので、しっかりと仕組みを把握した上で応用させてください。
最後に「NaN」に関する関数を紹介していきます。
「NaN」をどう扱っていけばよいのか理解できると思うので参考にしてください。
「NaN」に深く関係する「NumPy」については『【NumPy入門】機械学習はここから始める|計算方法、配列の作り方、配列の変形』を参考にしてください。
「NaN」とは?
「NaN」の読み方は「ナン」で、欠損値とも呼ばれています。
「NumPy」が提供するもので、利用するにはnumpyを読み込む必要があります。
どういった値かというと、「値がはいっていない値」です。
ちょっと謎ですよね。。。
イメージとしてはなにもないという新しい概念の数字のようなものです。
出力するとnanと表示されるので、プログラミング初心者のころnanという文字列かと思い==などで比較しようとしてました。。。
「NaN」の公式サイトにすべて記載されているので、詳細はこちらを参照ください。
「None」との違い

ある程度Pythonを触ってきた方でも、「NaN」と「None」の違いを理解できずに、なんとなく使っている方もいるのではないでしょうか。
そこで実際にコードを実行しながら、「NaN」と「None」がどう違うのか説明していきます。
まずは以下を実行して必要なモジュールを読み込みます。
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
from numpy import nan「NaN」はnumpy.nanで利用できるのですが、毎回書くのが面倒なのでnanで利用できるように設定しています。
それでは違いをみていきましょう。
型で比べる
まずは「NaN」のデータ型を調べてみましょう。
# NaN
type(nan)この結果はfloatとなります。
「NaN」は浮動小数点なのです。
つまり、floatの関数を利用することができ、計算することもできます。
3 + nanこの結果はnanとなります。
次は「None」についてみていきます。
# None
type(None)この結果はNoneTypeとなり、専用の型になります。
そのため計算で使用することはできません。
3 + Noneこの実行結果は以下になります。
TypeError: unsupported operand type(s) for +: 'int' and 'NoneType'このように計算に使おうとするとエラーが起こります。
論理値の違い
論理演算したときにも違いがあります。
以下を実行して試してみましょう。
print('NaN is True') if nan else print('NaN is False')
print('None is True') if None else print('None is False')このように出力されます。
NaN is True
None is Falseつまり、「NaN」はTrueとして扱われ、「None」はFalseとして扱われます。
「NaN」についての関数紹介

「NaN」について理解することができたら、実際に活用する方法を紹介します。
実際にコードを実行しながら進めていくので、上から順番に実行して理解を深めてください。
まず以下のコードを実行してデータを準備してください。
df = DataFrame([[1,2,3],[4,nan,5],[6,7,nan],[8,9,10],[nan,nan,nan]],
index=['I1','I2','I3','I4','I5'],
columns=['C1','C2','C3'])以下のデータが作成されます。
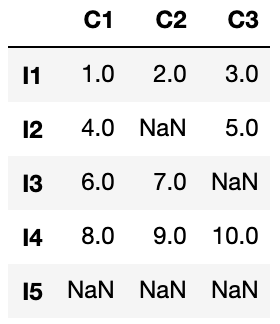
「DataFrame」に関しては『【Pandas入門】機械学習の基礎知識 -効率的な学習法-|調べて実践できる』を参考にしてください。
このデータを使用して、どういったことができるのか紹介します。
NaNの削除
「NaN」に関する削除を行う場合は”dropna関数”を使用します。
df1 = df.dropna()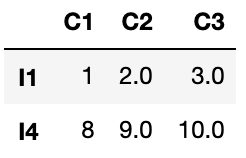
このように「NaN」が含まれる行が削除されます。
引数にhow='all'をいれると、すべての要素が「NaN」の行を削除します。
df2 = df.dropna(how='all')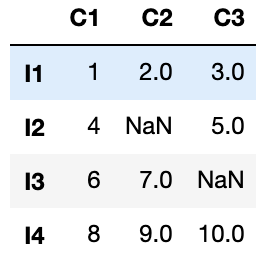
このようにすべての要素が「NaN」であるI5行が削除されました。
また、指定した個数以上のNaN値がある行を削除することもできます。
df3 = df.dropna(thresh=2)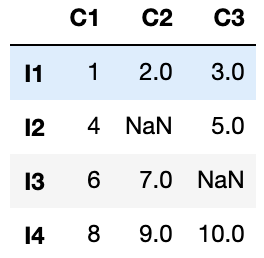
ここでは「NaN」が2つ以上ある行を削除しました。
このようにthreshを引数に設定することで実現できます。
これまでは行を削除してきましたが、axisを引数に入れることで、列を削除することもできます。
先ほど作成したdf3に足して実行してみます。
df4 = df3.dropna(axis=1)
このように、「NaN」がないC1列のみ残りました。
これらを組み合わせて必要ないデータを削除していきましょう。
NaNを埋める
「NaN」として入っているデータに具体的な数字を入れたい状況もあると思います。
その場合、”fillna関数”が役に立ちます。
df5 = df.fillna(0)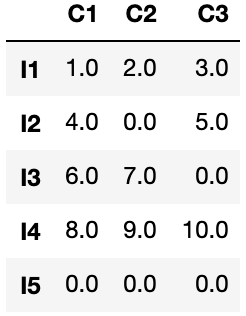
引数に0をいれて実行すると、すべての「NaN」が0になりました。
列ごとに埋める数値を変えることもできます。
df6 = df.fillna({'C1':1, 'C3':2})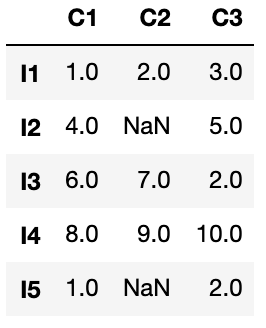
ここではC1列の「NaN」に1を、C3列の「NaN」に2を入れています。
ちなみに、これまで新しい変数にデータをいれてきましたが、実行した変数自体を変えることもできます。
df7.fillna(0, inplace=True)引数にinplace=Trueを入れることで、実行した変数自体を変えることができます。
NaNの判定
もっともよく使われており、すでに知っているかもしれませんが、「NaN」かどうか判定方法を紹介します。
それは”isnan関数”です。
np.isnan(df.at['I5','C1'])この結果はTrueとなります。
ちなみに「DataFrame」のat[(行), (列)]で表データに1つの要素にアクセスすることができます。
最後に
Pythonを触っていく上で「NaN」の利用は避けられないでしょう。
しっかりと、型はなにか、どういった値なのかを理解しておくことが重要です。
そうすることで、なにができて、できないのか判断することができます。
いくつか「NaN」に関する関数などを紹介してきましたが、他にもいくつかやり方があります。
すべて公式サイトに記載があるので、できそうと思ったことがあれば、調べてみてください(英語しかないですが、、、)。
独学で勉強されている方も多いと思いますが、やりたいことに関するジャンルについてまとまったオンライン講座がある『Udemy』を簡単に紹介します。
全部で10万以上もの講座あり、オンライン配信なので、いつでもどこでも学習することができます。
現在最大95%OFFキャンペーン中なので、自分のやりたい講座があれば受講をオススメします。
ちなみにぼくも『Udemy』で様々なプログラミンング関係(Python,データ統計,機械学習)を学びました。
最後まで読んでくださり、ありがとうございました!!!


コメント