
こんにちは、こがたです。
ディープラーニングについて概要がわかっても実際にコードを読み解かないと理解できないケースがあると思います。
そこで、この記事はPyTorchを利用してディープラーニングの基礎の基礎を実装しながら説明します。
- 機械学習に興味がある
- ディープラーニングを実装してみたい
- ディープラーニングをコードで理解したい
- サンプルコードを見てみたい
ディープラーニングの概要については↓↓↓をご覧になってください。

最初はPyTorchについて簡単に紹介します。
インストール方法やTensorFlowとの違いについても説明していきます。
そのあとはデータの準備からモデルを作成、学習して予測するまでの流れをコードをみながら解説していきます。
PyTorchの特徴とインストール方法
PyTorchはPythonの機械学習ライブラリです。
オープンソースなので、無料で利用することができます!
- コードがシンプルで描きやすい
- NumPyと近い
- 情報量が多い
- Define by Run
他の機械学習ライブラリよりもコードをシンプルに書くことができます。
大きな特徴としてはNumPyと関数が似ており、これまでやってきたことと同じような書き方で動かすことができます!

ディープラーニングというと「TensorFlow」を思い浮かべる人が多いかもしれません。
しかし、実は世界的にディープラーニングのライブラリでもっとも利用されているのは「PyTorch」です。
そのため、コミュニティもたくさんあり、情報量が多く、どんどん新しい技術が生まれています。
またTensorFlowは「Define and Run」であるのに対し、PyTorchは「Define by Run」です。
これは計算グラフを構築しながら、データを流すことができる仕組みです。
TensorFlowなどの「Define and Run」では構築してからデータを流してを繰り返すしかありません。
「Define by Run」方式をとれるのがPyTorchのもっとも大きな特徴といってもよいでしょう。
インストール
PyTorchをインストールするにはこちらの「INSTALL PYTORCH」で自分の環境を選択してください。
すると「Run this Command」に実行コマンドが表示されるので、そのまま実行すればインストールできます。
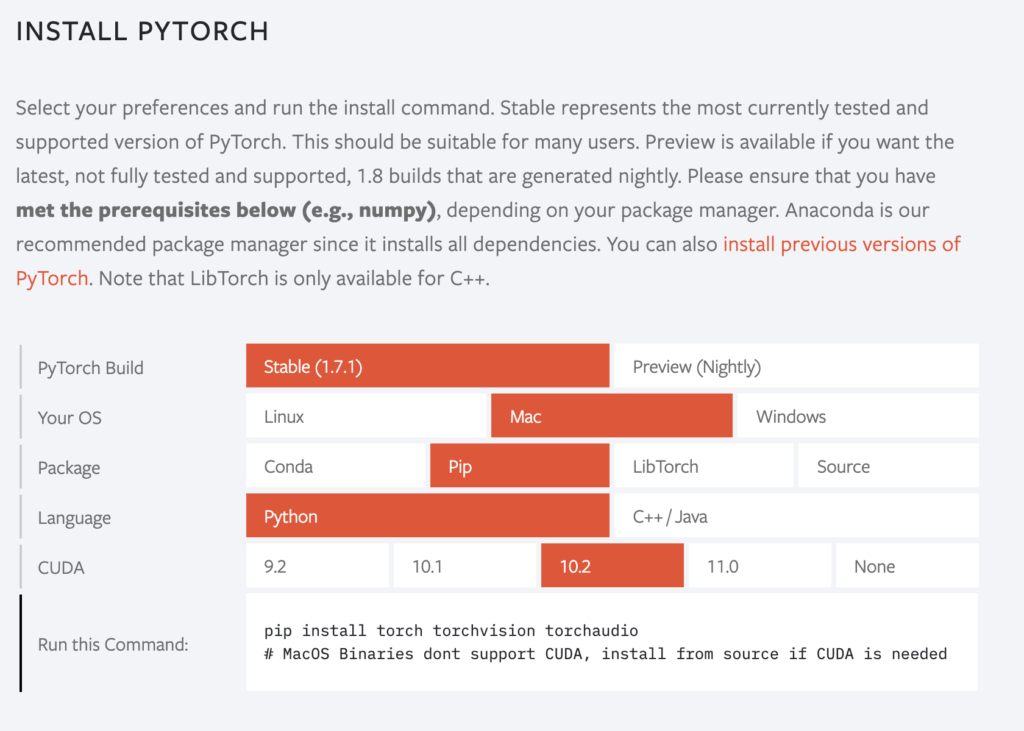
「PyTorch Build」は基本的に「Stable」を選択するようにしてください。
CUDAはGPUで動かすときに使用するものになります。
コードでディープラーニングを理解する
この記事では基本とされている手書き文字の認識をやっていきます。
以下の流れで進めていきます。
- モジュールの読み込み
- データの準備
- モデルの作成
- 学習
- 予測
上から順番に実行していけば同じように動くので手元で動かしてみてください!
※学習内容によって予測結果は異なるので、同じようにならないこともあります
モジュールの読み込み
PyTorch含め必要なモジュールを読みこみます。
import torch
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from torch import nn
from torch import optim「from sklearn import datasets」はデータを渡してくれるものです。
今回はdatasetsから画像データを読み込みます。
独自のデータを学習させていく場合は必要ありません。
「from sklearn.model_selection import train_test_split」はデータを訓練用とテスト用に分けてくれるモジュールです。
すべてのデータを訓練用とテスト用で使用する場合は必要ありません。
データの準備
ここではPyTorchで利用する形のデータを作成していきます。
まずは画像データを読みこんで表示してみます。
# データの取得
digits_data = datasets.load_digits()
# 画像データ
images = digits_data.data
# 正解データ
labels = digits_data.target
fig = plt.figure()
for i in range(10):
ax = fig.add_subplot(2,5, i+1)
plt.imshow(images[i].reshape(8, 8), cmap="Greys_r")
# 軸を非表示にする
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
print('全画像データ数:' + str(len(images)))
「datasets」で0〜9の画像データを読み込みます。
それを「pyplot」で表示しています。
ぼくが実行したときの画像データ数は「1797枚」でした。
この枚数を利用して画像を学習させていきます。
「pyplot」の利用方法がわからない方は↓↓↓をご覧ください。

# データを訓練用とテスト用に分ける
x_train, x_test, label_train, label_test = train_test_split(images, labels)
# Tensor型に変換
x_train = torch.tensor(x_train, dtype=torch.float32)
label_train = torch.tensor(label_train)
x_test = torch.tensor(x_test, dtype=torch.float32)
label_test = torch.tensor(label_test)「train_test_split」を使って画像データと正解データを訓練用・テスト用に分割しています。
テスト用データを作ることで「過学習」を防ぐことができます!
過学習とは似たようなデータばかり学習させて、汎用的にならない状態を言います。
PyTorchで扱うデータは「Tensor型」である必要があります。
そこで、「torch.tensor」関数で変換しています。
モデルの作成
基本的なモデルの作成と関数の設定をやっていきます。
# モデルの作成
model = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 10),
nn.ReLU()
)「Sequential」を利用してモデルを作成しています。
※この記事では基本を理解するためにクラスの作成は行いません
ここでは線形結合する「nn.Linear」を利用しています。
引数(64, 128)はニューロン数を設定しており、1つ目は入力、2つ目は出力を表しています。
そのため、2つ目は次の層の1つ目と同じ数値になります。
「ReLU」は活性化関数で0以下の場合は0、0以上の場合は「y=x」を返す関数です。
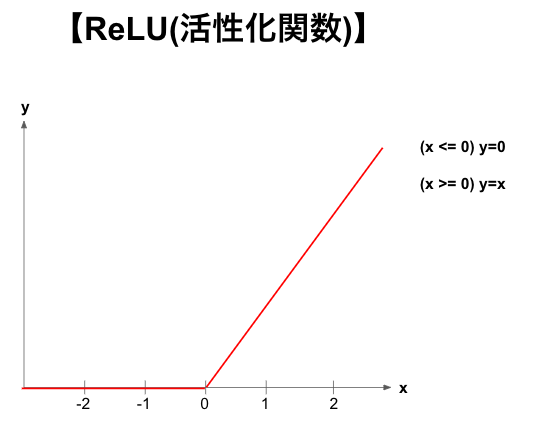
ほとんどのモデルでは「ReLU関数」が利用されています。
次に誤差関数、最適化アルゴリズムの設定を行います。
# 誤差関数
loss_func = nn.CrossEntropyLoss()
# 確率的勾配降下法(パラメータの最適化)→最適化アルゴリズム
optimizer = optim.SGD(model.parameters(), lr=0.01) 誤差関数に「CrossEntropyLoss」を設定しています。
ここで、予測したものと実際のデータがどれくらい違っているのか表して評価します。
「確率的勾配降下法」は誤差を減らしていくための1つアルゴリズムになります。
「lr」は学習率を表しており、どの程度パラメータを更新していくか設定します。
ここでは「SGD」を使用しているので学習率は一定になりますが、学習のたびに学習率が変わるアルゴリズムもあります(Adam,NAGなど)。
学習
実際に用意したデータ、モデルを使って学習させていきましょう。
# 誤差データ
loss_train_list = []
loss_test_list = []
# 学習開始
for i in range(1000):
# 勾配を0にする
optimizer.zero_grad()
# 順伝播→予測する
y_train = model(x_train)
y_test = model(x_test)
# 誤差関数で誤差の確認
loss_train = loss_func(y_train, label_train)
loss_train_list.append(loss_train)
loss_test = loss_func(y_test, label_test)
loss_test_list.append(loss_test)
# 逆伝播→勾配を求める
loss_train.backward()
# パラメータ(重み、バイアス)の更新
optimizer.step()
if i % 100 == 0:
print(str(i) + '回目学習: [訓練データの誤差]' + str(loss_train.item()) + ' [テストデータの誤差]' + str(loss_test.item()))ここでは1000回(エポック)学習させて、100回ごとに訓練用・テスト用の誤差を表示しています。

回数を重ねるごとに誤差が減っていっているのがわかると思います。
もう少しわかりやすくするためにグラフ表示してみます。
plt.plot(range(len(loss_train_list)), loss_train_list, label="Train")
plt.plot(range(len(loss_test_list)), loss_test_list, label="Test")
plt.legend()
plt.xlabel("Learning_num")
plt.ylabel("Error")
plt.show()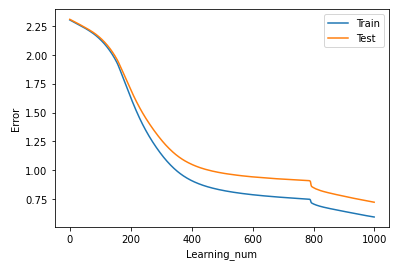
わかりやすく誤差が減っていますね。
- 入力データから予測値を割り出す(順伝播)
- 予測値と実際のデータを比較する(誤差関数を使用)
- 割り出した誤差を元に復習する(逆伝播)
- 次の予測をする
学習方法の詳細は↓↓↓をご覧ください。
予測
実際にデータを予測してみましょう。
import random img_id = int(random.uniform(0, len(images) -1)) x_pred = images[img_id] image = x_pred.reshape(8, 8) plt.imshow(image, cmap=”Greys_r”) # 軸を非表示にする plt.axis(“off”) plt.show() x_pred = torch.tensor(x_pred, dtype=torch.float32) y_pred = model(x_pred) print(“正解:”, labels[img_id], “予測結果:”, y_pred.argmax().item())
予測方法も簡単ですね。
予測したいデータをモデルに渡すだけです!
実際はもっと複雑なモデルを作ったり、適切な誤差関数を使ったりと多くのやり方があります。
ここではディープラーニングの基本をわかりやすくするために極力シンプルなコードを書いてきました。
学習方法
ディープラーニングを学ぶためには以下のことを理解していく必要があります。
- プログラミング(Pythonなど)
- ディープラーニングの細かい知識
- 各種関数の理解(数学)
- ディープラーニングの手法について
独学で学習していく場合はまず「Youtube」などの無料で学べるものを利用することをオススメします。
おそらくわからないことがでてきます。
それは「Udemy」を利用して深く学習していきます。
定期的にセールを行っており、1万円代の講座が1,000円代になります。
セール中に購入することをオススメします。

学習方法の詳細は↓↓↓の最後に記載してあるのでご覧ください。
最後に
ディープラーニングについて概要がわかっても、実際のコードを見なければ理解できないケースが多いです。
この記事で説明したコードを理解することができたらディープラーニングの基礎の基礎を理解することができたと思います。
あとは各種関数やモデルの組み方を理解して応用させていけば中級者レベルまで到達できます。
学習内容が多く、挫折しがちですが、諦めず学習を続けてください!
最後まで読んでくださり、ありがとうございました!!!


コメント